

Une plus grande rapidité de la notation, la mise en place de nouveaux verrous.
Résumé
Après avoir reprécisé dans quel cadre théorique pluridisciplinaire devraient être scientifiquement conçus les instruments d’évaluation de la compétence de production écrite des candidats qui présentent les examens du KPG, nous montrons comment ont fonctionné les instruments utilisés, de la session d’avril 2003 à celle de novembre 2007, pour la notation des copies remises par les candidats aux examens de français.
À partir d’analyses de scores réalisées au terme de chacune de ces sessions d’une part, et d’observations réalisées dans le centre de notation de l’autre, nous relevons les qualités et les défauts des instruments utilisés alors.
C’est sur la base de ce recensement, que nous tentons d’élaborer ensuite un instrument plus performant encore.
Une description détaillée de cet instrument et de son emploi est fournie.
Ses avantages aux plans docimologique (fiabilité, validité, sensibilité et constance) et ergonomique (rapidité, flexibilité, efficacité) sont enfin recherchés au fil de la présentation
– du protocole des premières expérimentations qui en ont été faites au cours de la session de mai 2008, aux épreuves de niveaux B1, B2 et C1,
– des réajustements opérés et
– des résultats issus de l’analyse statistique des scores enregistrés au cours de cette session.
Contexte
En 1999, le Ministère grec de l’Éducation et des Cultes a entrepris la mise en place d’un système national d’évaluation de la connaissance et de l’usage des langues étrangères : le KPG [39]. Ainsi, depuis 2003, des examens d’anglais, de français, d’italien et d’allemand sont organisés deux fois par an sur la base d’un programme commun, de spécifications identiques et à l’aide de mêmes outils de mesure des compétences de communication. [40]
La responsabilité scientifique de la conception des examens, de la rédaction des sujets et de la mise en œuvre des procédures d’évaluation a été confiée, pour chaque langue, à une équipe de chercheurs universitaires différente. [41]
Le cadre théorique dans lequel sont conçus les instruments d’évaluation des compétences de communication des examinés est nécessairement pluridisciplinaire.Ce sont bien évidemment les prescriptions propres aux champs (a) de la didactique et (b) de la docimologie qui jouent les rôles les plus déterminants dans l’établissement de la qualité du système.
a. Le cadre didactique est clairement défini dans la documentation publiée et disséminée par les services du Ministère. Un texte fondateur, justement intitulé Cadre Commun du Programme des Examens [42] définit l’objectif général de ces examens comme étant l’évaluation de l’usage socialement déterminé qui est fait de la langue pour la compréhension et la production de signes, dans le respect des normes du cadre socioculturel de leur production, par le biais de textes écrits ou oraux caractéristiques de divers genres de discours [43].
Ainsi, ce cadre commun recense entre autres :
– les modalités linguistiques et (inter)culturelles d’utilisation de la langue dont les candidats doivent prouver la connaissance,
– les activités communicatives auxquelles ils doivent être capables de prendre part,
– les genres de discours et de textes, oraux ou écrits, au contact desquels ils doivent pouvoir être placés,
– les environnements socioculturels dans lesquels peuvent s’intégrer les activités proposées et
– les domaines sociaux auxquels les candidats doivent être en mesure de se référer.
Ces descripteurs contraignent non seulement les caractéristiques des activités d’évaluation qui sont proposées aux examinés mais aussi les caractéristiques des documents sur le traitement desquels peuvent reposer certaines de ces activités.
Le KPG n’évalue donc pas de connaissances scolaires, ni ne réalise l’évaluation sommative de compétences acquises au terme de parcours éducatifs précis. Il prévoit au contraire d’effectuer l’évaluation et la certification de la connaissance pratique de certaines langues sur des objectifs spécifiques soigneusement sélectionnés au terme d’une analyse des besoins sociaux.
Cette approche va résolument dans le sens de la perspective actionnelle de l’usage et de l’apprentissage des langues promue par le Conseil de l’Europe et présentée dans le Cadre européen commun de référence pour les langues [44]. En témoignent, entre autres, les conclusions d’une sixaine de travaux de recherches entreprises, avec le soutien du Troisième Cadre Communautaire d’Appui, par les chercheurs du Laboratoire de Didactique des Langues du Département de Langue et Littérature française, sous la responsabilité scientifique du Professeur Aristea-Nikoleta Symeonidou-Christidou. [45]
b. Les moyens développés pour que soit garanti un degré de qualité docimologique maximal sont également énumérés dans la documentation fournie par les services du Ministère [46].
Ainsi, les qualités métrologiques de validité, de fiabilité, de sensibilité et de constance des examens sont systématiquement recherchées et notamment estimées par l’organisation d’une analyse statistique itérative des scores des examinés à chaque session.
Les sujets de libre production de discours écrit – que cet article concerne plus particulièrement – sont également pré-testés pour que soit confirmée, avant la finalisation de leur rédaction, leur réelle adéquation à l’objectif pour lequel ils ont été conçus. La qualité de ces sujets est aussi contrôlée sur la base d’une analyse docinomique [47] des résultats [48].
Les questions liées à la qualité didactique des sujets de l’épreuve de production écrite [49] ne seront pas abordées ici : seule, la question de la notation des copies sera traitée.
Le premier instrument de notation
De la session d’avril 2003 à celle de novembre 2007,un instrument très performant, créé par le Professeur Antonis Tsopanoglou, actuellement président du Comité Central d’Examen du KPG, a été utilisé pour la notation des copies remises par les candidats au terme de l’épreuve de production écrite des examens de français. Il peut être décrit dans les termes qui suivent [50].
Dans des lieux de passation sensiblement identiques [51] et dans un temps de passation suffisant [52], les candidats sont invités à rédiger [53] deux textes courts dans le respect de consignes et d’instructions.
Les compétences à développer sont d’un type actionnel puisque les candidats sont systématiquement placés dans une situation-problème [54] que la rédaction d’une lettre, d’un mot, d’un email, d’un rapport peut aider à résoudre. Il leur est par exemple demandé de proposer à un ami d’aller voir ensemble un spectacle, de réagir à un message publié sur des forums, bref, de développer des compétences de stratégie sociales nécessitant notamment la mise en œuvre des compétences de communication inhérentes.
Les productions écrites des candidats sont rassemblées dans un lieu central [55], sont notées par un corps permanent de correcteurs [56] sur la base de critères fixés, dans le respect des consignes du Comité central d’examen, par les équipes scientifiques. Chaque copie est notée par deux correcteurs [57] dont l’activité est dirigée et évaluée tout au long de la procédure d’évaluation.
Pour réduire autant que faire se peut l’influence de la subjectivité des évaluateurs, une grille d’évaluation est remise à chacun d’entre eux.Cette grille n’est pas à proprement parler remplie par le correcteur mais elle permet à ce dernier, en guidant sa réflexion, d’attribuer à chaque critère d’évaluation son importance relative.
Les critères, ou groupes de critères, d’évaluation figurant dans cette grille peuvent être classés en trois catégories : la bonne réalisation des intentions fixées par la consigne, dans le respect des instructions qui l’accompagnent (compétence pragmatique), le respect des normes sociolinguistiques imposées par la situation de communication proposée (compétence sociolinguistique) et le respect des normes proprement linguistiques (compétence linguistique : lexique, morphosyntaxe, orthographe, lisibilité).
L’indication du numéro des descripteurs du Cadre commun des examens auquel correspond chacun des critères montre que ces derniers répondent bien aux prescriptions des concepteurs et aux attentes des examinés.
Ces critères et leurs degrés de réalisation potentiels sont présentés sur trois colonnes. La nature des critères est définie dans les en-têtes de ces trois colonnes. Les correcteurs doivent déterminer et indiquer le degré de réalisation de chacun de ces critères, en opérant d’abord un choix binaire portant sur la recevabilité de la copie puis, suivant le cas,
– un choix ternaire entre les options tout-à fait hors sujet, texte incompréhensible, aucune réponse / quelques mots épars ou, beaucoup plus souvent,
– un choix ternaire entre les options très satisfaisant, moyennement satisfaisant, peu satisfaisant suivi de deux choix binaires entre les options peu de fautes et beaucoup de fautes [58], puis entre oui et non.
En passant d’une colonne à l’autre, chacun des évaluateurs suit donc un itinéraire arborescent qui est fonction de ses choix successifs et qui le conduit à un score situé sur une échelle constituée de valeurs discrètes ordonnées, s’étendant de 1 à 15 (fig. 1). Au total, quatre décisions doivent donc généralement être prises par le correcteur.

Lorsqu’il a fini d’évaluer les deux productions du candidat, le correcteur reporte sur le formulaire adéquat la somme des deux scores auxquels il a été successivement conduit. Le personnel administratif du centre de correction est ensuite chargé de démasquer les scores attribués par chacun des deux évaluateurs et de vérifier si les écarts entre les deux scores ne sont pas trop importants. Si un écart anormal est repéré, un arbitrage est réalisé par un troisième évaluateur.Le reste du traitement est effectué automatiquement : lecture optique des scores, moyennage [59] et stockage informatique.
Le degré d’efficacité de l’outil semble élevé. En effet, au fil des sessions, on constate que les courbes de distribution des résultats à l’épreuve de production écrite ont une allure normale (courbe gaussienne, coefficients d’asymétrie réduits) et que la corrélation entre les notes attribuées par deux correcteurs différents à une même copie (fidélité interjuge) est constante et forte.
Cette rare qualité doit être signalée. En effet, les études statistiques réalisées par Piéron (1963), par Reuchlin (1971), par De Lansheere (1976) ou, plus récemment par Merle (1996) montrent toutes que les résultats à une épreuve d’expression écrite sont en partie dus au hasard de l’attribution d’une copie à tel ou tel correcteur. La plupart des expériences de multicorrection aboutissent aux mêmes conclusions : l’évaluation par le jugement humain est peu fiable. La qualité de l’instrument de notation est donc manifeste mais quelques questions peuvent – et doivent ! – malgré tout être posées :
1) La grille de notation est-elle systématiquement utilisée par le correcteur ?
L’observation du travail des correcteurs sur le terrain a montré que certains d’entre eux, à vrai dire, rompus à cette tâche d’évaluation, utilisent parfois la grille comme un simple instrument de « remise à l’heure des horloges ». Dans ce cas, la fiabilité de l’évaluation est bien entendu menacée.
2) La structure arborescente de la grille permet-elle une évaluation fiable et surtout l’évaluation de tous les cas de figure ?
La sempiternelle question de la pondération des scores [60] se pose en effet ici. Ainsi, par exemple, suivant la version [61] de la grille utilisée, la réalisation des critères de lisibilité ou de qualité orthographique est tantôt notée, tantôt pas ; la réalisation des critères de qualité lexicale permettent l’obtention d’un seul point sur 15 (6,6% de la note maximale) ou de trois points sur 15 (20%). La motivation de ces différences de pondération entre les compétences ne semble pas avoir été expliquée dans la documentation publiée par le Ministère.
De plus, le fait que les choix opérés entre les 29 options potentielles soient contraints par la structure arborescente de leur organisation fait se poser la question du bien fondé des relations de subordination critérielle qu’impose cette dernière.Ce rapport de subordination, observé au cours de l’analyse de la grille utilisée jusqu’en novembre 2007, de certaines compétences à d’autres pourrait empêcher une notation objective : on ne peut pas toujours estimer avec précision et avec certitude dans quelle mesure le développement insuffisant d’une compétence précise influe sur le degré d’efficacité globale de la production.
Il a été montré qu’une même imperfection relevée dans deux productions différentes peut avoir des retentissements d’importances très diverses sur l’efficacité finale des écrits dans lesquels elle s’intègre. [62] Ainsi, par exemple, un très petit nombre de fautes d’orthographe, même mineures, peut compromettre l’efficacité d’une lettre de candidature par ailleurs fort bien construite. Un plus grand nombre de fautes d’orthographe pourrait ne pas gêner le destinataire d’une carte postale envoyée de vacances par un ami étranger. Tout dépend ici des composantes de la situation de communication.
Ceci étant dit, dans deux situations de communication identiques, l’importance relative des performances déployées peut aussi varier. Et c’est d’ailleurs le problème qui se présente à d’assez nombreuses reprises lorsque des évaluateurs ne trouvent pas dans la seconde colonne et en regard de la première option qu’ils ont cochée, des descripteurs correspondant aux qualités de l’écrit évalué. Il peut, en effet, parfois arriver qu’une production peu satisfaisante au plan de la réalisation des intentions et du respect des normes sociolinguistiques soit pourtant très satisfaisante aux seuls plans syntaxique et lexical, ou vice-versa. La notation de ces cas de figure n’est pas prévue par la grille.
3) N’est-il pas possible d’encore simplifier la procédure de notation ?
L’utilisation de la grille de notation reste assez lourde dans la mesure où le correcteur doit prendre jusqu’à quatre décisions successives, noter le score correspondant sur une feuille de brouillon, effectuer à nouveau cette procédure pour le second écrit, calculer le total des scores et reporter ce dernier sur le formulaire adéquat.
4) Le calcul de la note est-il tout à fait transparent ? Peut-il être contrôlé ?
Le calcul, effectué mentalement, de la note totale (addition des notes attribuées à chacun des deux écrits) rend par ailleurs l’analyse des scores plus difficiles dans la mesure où la note totale enregistrée peut, sous un aspect normal, résulter du calcul de la moyenne de deux notes particulièrement – et peut-être anormalement –divergentes. En neutralisant les écarts, ce système ne contrôle peut-être pas suffisamment les possibilités d’erreurs dans la notation de chacune des productions, considérées séparément. Il est aussi possible que des erreurs de calcul mental surviennent et ne soient jamais découvertes.
5) L’absence de seuils de réalisations opérationnels ne freine-t-elle pas le travail de notation ?
Les degrés de réalisation des descripteurs repris dans la grille sont peut-être formulés en des termes qui donnent une trop grande latitude à la subjectivité des correcteurs. Comment peuvent-ils en effet concrètement distinguer l’écrit moyennement satisfaisant de l’écrit peu satisfaisant ? À partir de quel nombre de fautes peuvent-ils considérer qu’elles sont nombreuses ?
En l’absence de seuils de réalisation concrets et précis, les évaluateurs hésitent parfois trop longtemps entre les options offertes, surtout pour le premier choix, justement celui qui fait perdre ou gagner un nombre plus considérable de points (4 points sur 15, soit plus de 25% de la note).
Ces cinq questions concernent d’une façon ou d’une autre les qualités didactiques et métrologiques de l’évaluation. C’est donc de la nécessité d’y répondre qu’est née l’hypothèse que nos recherches ont tenté de confirmer à savoir qu’il est possible de concevoir un instrument de notation qui soit plus efficace encore aux plans ergonomique et docimologique.
La construction d’un outil a ainsi été réalisée sur la base des considérations qui précèdent. Ce nouvel instrument de notation et les principes de son fonctionnement seront présentés dans les pages qui suivent. Les résultats de la tentative de validation par l’analyse et par l’expérimentation de ses qualités didactiques et métrologiques seront livrés ensuite.
Le nouvel instrument de notation
Pour chaque niveau, le matériel de notation consiste en un document de 3 ou 4 pages reliées comportant
– l’impression polychrome d’une grille de notation (fig. 2), encadrée par deux listes, une par sujet, (fig. 3) d’objectifs à atteindre, exprimés en termes de performances attendues,
– la reproduction fidèle des consignes et instructions qui ont été adressées aux examinés.
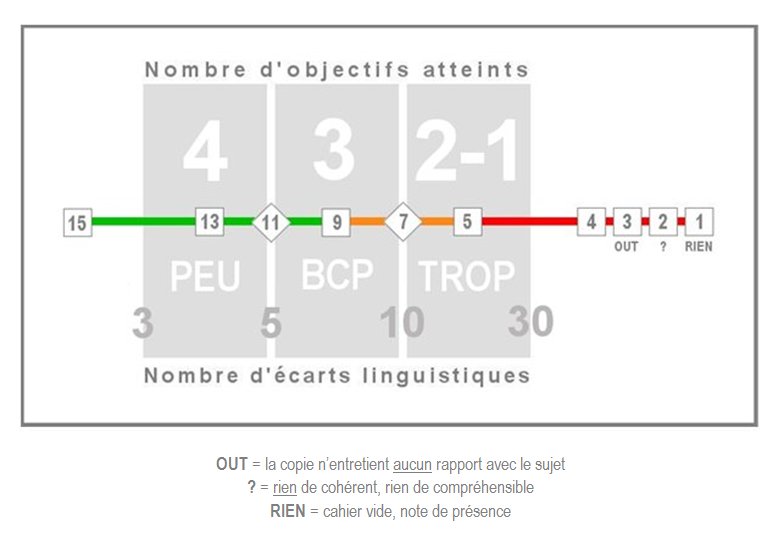
La grille de notation, identique pour les deux activités mais qui peut légèrement différer d’un niveau à l’autre, est constituée de six zones grisées réparties en deux rangées.

La rangée supérieure permet au correcteur d’indiquer le nombre des performances attendues effectivement réalisées par le candidat. La description de ces performances attendues est faite en des termes qui renvoient aux compétences pragmatique, sociolinguistique et de stratégie. Chaque zone correspond à un nombre de performances indiqué en blanc (4,3 ou 2-1).
Avant de définitivement considérer un objectif (fig. 3) comme atteint, le correcteur est invité à vérifier si le non respect des contraintes sociolinguistiques imposées par la situation n’en empêche finalement pas la bonne réalisation (respect de normes sociolinguistiques) et à se demander si l’allocutaire réagira bien comme l’attendent le locuteur et la consigne d’activité (efficacité de l’écrit).
En pratique, le correcteur doit s’identifier au destinataire de l’écrit et se demander si le scripteur a réalisé les intentions fixées par la consigne, d’ailleurs reproduites sur la même page que la grille [63].

La rangée inférieure de la grille de notation (fig. 2) permet d’indiquer le nombre d’écarts relevés par rapport aux normes du système de la langue (orthographe, morphologie, syntaxe, lexique, etc.). On ne traite donc ici que la qualité linguistique de l’écrit.
Le dénombrement des mots soulignés peut être approximatif. Ainsi, dans la grille reproduite dans ces pages (Fig. 2), un écrit comportant 11 ou 12 écarts peut être rangé dans la zone « BCP 5-10 » si l’évaluateur estime qu’un certain nombre de ces fautes sont d’une importance mineure. Ce réajustement devrait rester occasionnel.
Le correcteur pose ensuite un doigt au centre de la zone de la rangée supérieure correspondant au nombre des objectifs attendus effectivement atteints par l’examiné.
Il pose un second doigt au centre de la zone de la rangée inférieure correspondant au nombre de mots soulignés dans la copie.
La note à reporter sur le formulaire adéquat est celle qui figure dans le carré ou dans le losange situé exactement à mi-chemin entre les deux zones pointées des doigts par le correcteur (fig. 4).

Si le correcteur pense que cette note ne reflète pas la valeur subjective qu’il prête lui-même à l’écrit, il peut ajouter ou retrancher un, et un seul, point. C’est la seule marge de manœuvre laissée à sa subjectivité.
Si plus de 30 écarts linguistiques sont dénombrés ou qu’aucun objectif n’est atteint, la note ne peut en aucun cas dépasser 4 [64].
La note maximale est attribuée lorsque les 4 objectifs sont atteints et que le nombre d’écarts linguistiques est inférieur à 3 [65].
Les avantages que semble comporter cette grille et ce barème sont les suivants :
a. Par une simple modification des valeurs renseignées, il est possible d’adapter la grille et le barème à un type d’activité ou à un niveau particulier [66]
b. La grille est commune aux deux sujets, ce qui amoindrit le risque de confusion lors de l’évaluation successive des deux productions d’un même examiné.
c. Les objectifs pragmatiques sont exprimés en termes de performances (le plus souvent des micro-fonctions) dont le seuil de réalisation est concret [67] (réalisation effective de l’acte et de l’intention).
d. Le nombre des objectifs est systématiquement limité et fixé à 4.
e. Le calcul de la qualité de la compétence pragmatique est réalisé à partir d’une appréciation quantitative, plus opérationnelle et donc plus objective.
f. Dans la grille proprement dite (fig. 2), la formulation des descripteurs est réduite à 13 mots (contre 80 environ dans le premier instrument), toujours identiques d’une grille à l’autre.
g. Des seuils chiffrés (nombre de fautes) autorisent un calcul de la qualité linguistique réalisé à partir d’une appréciation quantitative, plus objective.
h. La coloration de la ligne horizontale centrale permet au correcteur d’avoir toujours en tête la signifiance de la note (éliminatoire, inférieure à la moyenne générale exigée, supérieure à la moyenne générale exigée). Cette information peut l’inciter à considérer deux fois plutôt qu’une le bien fondé des choix qu’il a opérés.
i. Le placement hors zones des notes extrêmes dont l’attribution doit rester occasionnelle fait aussi reconsidérer le bien fondé des choix effectués.
j. La mise en page permet d’effectuer mécaniquement un calcul, facile et donc fiable, de la note finale.
k. La marge de manœuvre de la subjectivité du correcteur est réduite à 1, ce qui assure une notation plus fiable.
l. Il est possible de traiter équitablement des cas de figure extrêmes, mais néanmoins possibles, comme celui d’examinés parvenant à réaliser, malgré 25 fautes de langues commises,les 4 objectifs impartis : ils obtiendront 9 sur 15 alors que dans la grille du premier instrument de notation, ils auraient obtenu, soit 12 sur 15 si le correcteur avait respecté l’arborescence, soit 4 sur 15 si le correcteur avait décidé de choisir la note qui se trouve en regard du degré de réalisation de la seule performance linguistique.
m. Dans la plupart des cas, le nombre des décisions à prendre est réduit de quatre (premier instrument de notation) à deux : nombre d’objectifs atteints, nombre d’écarts linguistiques.
n. Si l’écrit n’est pas recevable : le correcteur choisit simplement entre trois caractérisations redéfinies [68] (aucun rapport avec le sujet, rien de cohérent ou cahier vide).
o. La possibilité est donnée au correcteur de consigner dans une zone réservée à cet effet les dysfonctionnements éventuels, les difficultés qu’il a pu éprouver, la description d’un cas de figure imprévu, une remarque adressée aux concepteurs de l’épreuve et/ou aux rédacteurs des sujets.
p. Les consignes, les instructions et les documents donnés aux examinés sont reproduits – et donc plus probablement consultés – sur la ou les pages qui suivent directement celle où figure la grille.
q. L’emploi systématique de la grille et le respect du barème par les correcteurs sont pratiquement assurés puisque ces derniers devront nécessairement pointer du doigt deux zones significatives de la grille pour pouvoir calculer la note à attribuer.
Validation
L’expérimentation de la grille s’est faite de quatre façons.
a. La grille a été appliquée par trois juges expérimentés [69] sur des échantillons extraits de l’ensemble des copies à corriger au cours des sessions de mai 2008 puis par un seul juge [70] en novembre 2008. Ces expérimentations avaient pour but premier d’étalonner l’instrument pour chaque niveau. L’étalonnage consistait essentiellement à déterminer les valeurs qui allaient représenter les seuils de réalisation des critères considérés, en d’autres termes les valeurs permettant de distinguer l’une de l’autre les six zones de la grille de notation. Les travaux d’étalonnage ont simplement consisté en l’établissement préalable de la normalité [71] des courbes de distributions des notes pour chaque niveau et pour chaque activité puis en la définition de seuils permettant l’établissement d’une moyenne des notes et d’un écart-type comparables à ceux des sessions précédentes.
b. Elle a aussi été expérimentée au cours d’un stage assurant la formation de 15 nouveaux membres du corps permanent des correcteurs, organisé dans le cadre d’un programme soutenu par le Troisième Cadre Communautaire d’Appui et placé sous la responsabilité scientifique du professeur Rinetta Kigitsioglou-Vlachou.
Des activités visant le calibrage et l’établissement de standards [72] y ont été organisées. Lors d’une séance de correction pilote effectuée au terme de cette formation, il est apparu que, si les outils de mesure de la compétence linguistique étaient fiables (3 écarts interjuges seulement sur 105 corrections), ceux qui mesurent la compétence pragmatique l’étaient moins (22 écarts). Le perfectionnement de l’outil a consisté en une amélioration de la formulation des objectifs pragmatiques (de part et d’autre de la grille proprement dite) et des instructions aux correcteurs inhérentes.
c. La grille a aussi été expérimentée au cours des deux formations de correcteurs qui précédaient immédiatement la correction des copies des sessions de mai et de novembre 2008. Faute de moyens, les taux de fidélité interjuge, pourtant très élevés, n’ont hélas pas été actés. Il reste que cette forte corrélation était obtenue au terme de travaux collaboratifs et qu’elle n’était donc pas nécessairement représentative de celle qui serait établie au terme de chaque session.
d. Enfin, la grille a été utilisée pour la correction de l’ensemble des copies au cours de ces deux mêmes sessions. Durant cette dernière étape, plus aucun ajustement n’a pu être opéré sous peine de compromettre la constance – et donc l’équité – de l’évaluation. Toutefois, l’étape finale revêtait un intérêt particulier : elle allait notamment permettre d’analyser des statistiques plus significatives puisqu’elles allaient porter sur la totalité des actions évaluatives réalisées au moyen de cet instrument au cours d’une même session [73].
Les résultats des analyses statistiques ont été les suivants.
À chacun des quatre niveaux, les courbes de distributions se révèlent normales, suffisamment symétriques, similaires d’une année à l’autre [74] pour les niveaux B1, B2 et C1 [75] (fig.5), et le degré de fidélité interjuge, simplement estimé sur la base du résultat du calcul du coefficient de corrélation de Bravais-Pearson entre les notes attribuées par les correcteurs à de mêmes copies, s’est révélé similaire d’une année à l’autre également, tout comme les moyennes et les écarts-types, d’ailleurs (fig. 6).
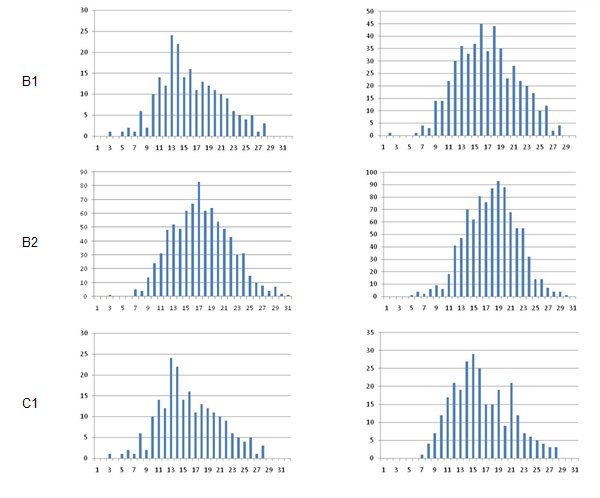
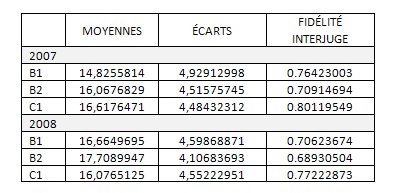
La comparaison entre les nuages de points, dans les deux graphiques qui suivent (fig. 7), permet de constater que le degré de corrélation entre les notes attribuées à une même copie (fidélité interjuge) est élevé (courbes de tendances linéaires coïncidant presque avec la diagonale),sensiblement le même d’une année à l’autre, comme en témoigne l’inclinaison presque identique des courbes de tendance. On observe toutefois à la session de mai 2008 – et au contraire de la session de mai 2007 – que les notes extrêmes sont en corrélation plus étroite (le nuage forme une ellipse plus oblongue aux deux sommets) et qu’absolument aucun désaccord interjuge hors normes n’a été relevé (aucune note ne se détache du nuage). Ces observations reflètent une augmentation du degré de fiabilité de l’instrument.
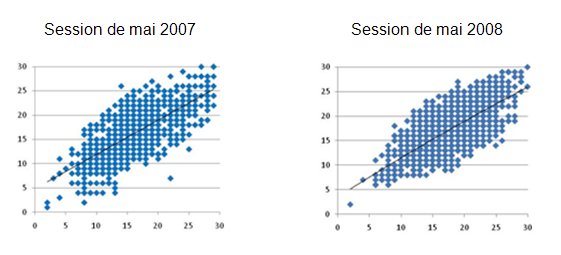
Sur le terrain, le travail des correcteurs s’est effectué beaucoup plus rapidement et certainement plus efficacement puisqu’aucune anomalie dans les notes n’a été décelée, puisqu’absolument aucun arbitrage interjuge n’a été nécessaire.
Les variables disponibles pour juger de la fiabilité du dispositif de notation n’ont pas pu être toutes exploitées dans la mesure où leur nombre était sensiblement moindre aux sessions organisées avant la date de première utilisation du nouvel instrument.
Ainsi, par exemple, les risques d’erreurs et l’opacité du calcul des notes ont été récemment éliminés par la décision du Comité Central de faire imprimer de nouveaux formulaires imposant le report séparé des deux notes à additionner. Cette mesure permet d’écarter désormais le risque d’une erreur de calcul et d’analyser séparément les notes attribuées à chacun des deux écrits d’un même candidat. De la même façon, les gros écarts entre les notes attribuées par deux correcteurs à un même écrit peuvent être repérés, eux aussi, et analysés.
Il est donc aujourd’hui possible d’identifier les correcteurs et de connaître la note attribuée par ces correcteurs à chacune des deux activités. Ces nouvelles variables vont permettre de neutraliser certains facteurs – comme, par exemple, les écarts systématiquement liés à l’identité d’un correcteur (d’un couple de correcteur) particulier ou aux caractéristiques d’une activité mal construite – qui peuvent parasiter ou biaiser l’estimation de la fiabilité de l’instrument de notation proprement dit. Mais pour que ces variables soient exploitables, il est nécessaire que les données statistiques brutes issues des résultats à deux sessions au moins soient accessibles aux chercheurs. Ce qui n’est pas encore le cas [76].
De ces premières expérimentations et de l’analyse des variables actuellement exploitables, il ressort que le nouvel instrument comporte des avantages aux plans ergonomique et docimologique.
Il a été montré qu’au plan ergonomique, cet instrument permet
a. une plus grande rapidité de la notation (constatée par les responsables et reconnue par les correcteurs) des copies, favorisée par l’unicité de la grille destinée à la notation des deux écrits, par l’amoindrissement du nombre des objectifs dont la réalisation doit être constatée, par une réduction substantielle de la longueur des formulations et du nombre des décisions à prendre, et surtout par la possibilité d’exprimer le degré de réalisation des critères par des valeurs discrètes ;
b. la mise en place de nouveaux verrous de sécurité comme l’utilisation de la couleur pour rappeler la signifiance des notes, le placement hors zones des notes extrêmes, une mécanisation du calcul de la note, la réduction à un seul point de la marge de manœuvre laissée à la subjectivité, l’impossibilité d’attribution d’une note sans que la grille soit utilisée, la proximité des consignes données au cours de l’examen ;
c. une plus grande flexibilité de la notation désormais adaptée à tous les cas de figure, même les plus extrêmes, adaptable à tous les types de sujets et facilement étalonnable.
Au plan docimologique, si ces améliorations d’ordre ergonomique ne semblent pas, dans les chiffres, avoir contribué à quelque augmentation spectaculaire des degrés de fiabilité, de validité, de sensibilité ou de constance de la procédure de notation, elles ont au moins le mérite de ne pas avoir non plus contribué à amoindrir les qualités métrologiques traditionnelles de l’épreuve.
Il a par ailleurs été montré que les notes extrêmes sont attribuées avec plus de fiabilité et que les cas de désaccords manifestes entre juges ont disparu.
Le comportement de certaines variables, auxquelles nous avons accès depuis mai 2008 seulement, font soupçonner une influence de la nature de l’activité langagière à évaluer (production vs médiation) et de la constitution des couples de correcteurs sur le degré de fidélité interjuge. S’il nous est permis, au terme des prochaines sessions, de répéter nos mesures, la neutralisation de ces facteurs parasites permettra d’estimer avec plus de précision les qualités métrologiques de l’instrument de notation et ainsi, d’encore affiner notre outil.
Références bibliographiques
Conseil de l’Europe / Conseil de la Coopération culturelle / Comité de l’éducation / Division des langues vivantes et Didier (éds), 2005 – « Cadre européen commun de référence : apprendre, enseigner, évaluer », 2e éd., Strasbourg-Paris.
Conseil de l’Europe, 2003 – « Relier les examens de langues au Cadre européen de référence pour les langues : Apprendre, enseigner, évaluer (Cadre européen commun de référence) », Strasbourg, Division des Politiques Linguistiques, 2003. – Site du Conseil de l’Europe. [En ligne] http://culture2.coe.int/portfolio/documents/cadrecommun.pdf, dernière consultation le 04/07/2008.
De Landsheere, G., 1976 – Introduction à la recherche en éducation. A. Colin-Bourrelier, Paris.
Delhaye O., 1998 – Présentation critique d’un instrument d’évaluation mis en œuvre en Grèce pour l’octroi d’une certification en langue française, Mémoire de DEA – Sciences du langage, Université de Mons-Hainaut, Mons. [En ligne] http://gallika.net/tvx, dernière consultation le 07/09/2008.
Delhaye O., 2006a – Modèle d’évaluation des dispositifs et des techniques d’évaluation certificative en langues étrangères, Thèse de doctorat en sciences du langage et de la communication, Université Aristote de Thessaloniki.
Delhaye O., 2006b – « Évaluation certificative - Certification internationale de la connaissance d’une seule langue vs certification nationale de la connaissance de plusieurs langues », Edufle.net, ISSN 1773-0511.
Hadji Ch., 1997 – L’évaluation démystifiée. ESF, Paris.
Meirieu Ph., 1987 –Apprendre… oui, mais comment ?, Éditions ESF, Paris.
Merle P., 1996 – L’évaluation des élèves, enquête sur le jugement professionnel. PUF, Paris
Milanovic M., 2005 – « Évaluation de compétences en langues et conception de tests », in Site du Conseil de l’Europe.
[En ligne] http://culture2.coe.int/...revoctobre.doc, dernière consultation le 07/09/2008.
Ministère grec de l’éducation nationale et des cultes (éd.), 2005 – Certificat d’État de Connaissance des Langues. Livret d’informations, Athènes.
Ministère grec de l’éducation nationale et des cultes, Certificat d’État de Connaissance des Langues - Section du site du ministère consacrée au CECL
[En ligne] http://www.KPG.ypepth.gr, dernière consultation le 07/10/2008.
Noizet G. et Bonniol J.-J., 1969 – « Pour une docimologie expérimentale », in Bulletin de Psychologie, 1968-1969.
Piéron H., 1963 – Examens et Docimologie. PUF, Paris.
Reuchlin M., 1971 – Traité de psychologie appliquée. PUF, Paris.
Αριστοτέλειο Πανεπιστήμιο Θεσσαλονίκης, Φιλοσοφική Σχολή, Τμήμα Γαλλικής Γλώσσας και Φιλολογίας, Τομέας Γλωσσολογίας και Διδακτικής, 2008 – Παρουσίαση των υφιστάμενων συστημάτων πιστοποίησης γνώσης γαλλικής γλώσσας που είναι στη διάθεση των ελλήνων πολιτών και ανάλυση των οργάνων μέτρησης που χρησιμοποιούνται από αυτά (non publié).
Υπουργείο Εθνικής Παιδείας και Θρησκευμάτων (εκδ.), 2003. – Κρατικό Πιστοποιητικό Γλωσσομάθειας. Ενημερωτικό Έντυπο, Αθήνα.
Υπουργείο Εθνικής Παιδείας Και Θρησκευμάτων, Κρατικό Πιστοποιητικό Γλωσσομάθειας, 2003 –Ενιαίο Πλαίσιο Προγράμματος των Εξετάσεων. [En ligne] http://www.ypepth.gr/el_ec_category2403.htm, dernière consultation le 04/07/2008.
Annexes
Grille de notation initiale pour l’activité 1, niveau B1
Nouvel instrument de notation
Instructions aux correcteurs
Mode d’emploi de la grille de notation
Grille et barème de notation (niveau B1, novembre 2008)
Rappel des consignes (niveau B1, novembre 2008)
Portfolio
Cet article a été publié dans Ζητήματα πιστοποίησης της γλωσσομάθειας : Το Κρατικό Πιστοποιητικό Γλωσσομάθειας ως σημείο αναφοράς, Θεσσαλονίκη : Εκδόσεις Μαλλιάρης-Παιδεία, 2009.
__________
[1] Transcription latine du sigle du dispositif dénommé Κρατικό Πιστοποιητικό Γλωσσομάθειας en grec (Certificat d’État de Connaissance des langues).
[2] Cf. description dans Ministère de l’éducation nationale et des cultes (2005).
[3] Ces chercheurs sont employés par l’Université nationale Capodistrienne d’Athènes et par l’Université Aristote de Thessaloniki.
[4] En grec : Ενιαίο Πλαίσιο Προγράμματος των Εξετάσεων – ΕΠΠΕ (2003).
[5] Cf. Υπουργείο Εθνικής Παιδείας και Θρησκευμάτων (2003 : 15).
[6] Conseil de l’Europe (2001).
[7] Cf. notamment Αριστοτέλειο Πανεπιστήμιο Θεσσαλονίκης, Φιλοσοφική Σχολή, Τμήμα Γαλλικής Γλώσσας και Φιλολογίας, Τομέας Γλωσσολογίας και Διδακτικής (2008).
[8] Cf. résumé suffisant in Delhaye (2006b).
[9] À prendre au sens prêté par Noizet et Bonniol (1968-1969) d’investigation docimologique qui dépasse le plan du constat et qui permet un perfectionnement du système d’estimation par la connaissance expérimentale des mécanismes en jeu et des causes de distorsion dans leur fonctionnement.
[10] Cf. Υπουργείο Εθνικής Παιδείας και Θρησκευμάτων (2005 : 29-30).
[11] Elles ontétudiées au cours d’autres recherches entreprises par le Département de Langue et Littérature française avec le soutien du Troisième Cadre Communautaire d’Appui et dont les résultats ne sont pas encore publiés.
[12] Cette description n’est pas réalisée par l’auteur de cette grille et peut donc comporter des lacunes.
[13] Il s’agit le plus souvent d’écoles publiques.
[14] Ce temps est régulièrement réévalué.
[15] Ces textes sont à compéter, parfois, au niveau A.
[16] Au sens entendu par Meirieu (1987 : 164-179).
[17] Dans le centre de notation d’Athènes ou de Thessaloniki.
[18] Le travail des évaluateurs des productions écrites ne consiste certainement pas à les corriger, mais nous conserverons cette dénomination souvent adoptée, notamment dans le Cadre Commun du Programme des Examens du KPg (2003).
[19] Mansour (1978) a montré qu’il faut au moins 7 évaluateurs pour assurer une évaluation fiable d’une même production écrite mais que ce nombre peut être sensiblement réduit si ces évaluateurs disposent d’une même grille d’évaluation.
[20] Les formulations exactes sont plus longues : Aucune faute ou très peu, qui ne gênent pas du tout la compréhension – Quelques fautes qui ne gênent pas vraiment la compréhension – Peu de fautes qui commencent à gêner la compréhension – Beaucoup de fautes qui commencent à gêner la compréhension – Beaucoup de fautes qui finissent par gêner quelque peu la compréhension – Beaucoup de fautes ou grosses fautes. Le lecteur doit relire certains passages pour comprendre (traduit du grec). Cf. Première grille en annexe
[21] Calcul de la moyenne des scores attribué par chacun des évaluateurs.
[22] Cf. par exemple Delhaye (2006 : 18-19).
[23] La grille se décline en plusieurs versions suivant le niveau, l’activité langagière (pure production / médiation) ou la session.
[24] Cf. Delhaye (1998 : 57).
[25] Hadji (1997 : 24-28) déduit de cette intrusion du subjectif dans la notation que l’évaluation n’est finalement pas une opération de mesure, mais avant tout un jugement humain. Il revient au concepteur d’une grille de notation de proposer une catégorisation facile des jugements émis.
[26] Le correcteur ne devra donc poser aucun doigt sur les zones grisées de la grille dans ce cas extrême puisque le nombre des objectifs atteints et celui des écarts linguistiques ne sont pas mis en rapport.
[27] Ce cas de figure, rare, ne peut être représenté par les mêmes relations géométriques, c’est pourquoi il figure également en dehors des zones grisées.
[28] C’est pourquoi d’ailleurs, une mention explicite est toujours faite du sujet précis auquel se rapporte chaque grille.
[29] On pourrait objecter que les adjectifs suffisant et efficace renvoient à des notions relatives, mais elles sont clairement explicitées dans la littérature remise aux correcteurs. Cf. Instrument en annexe.
[30] Nous avons reformulé les descripteurs pour éviter le chevauchement qui pouvait exister entre texte incompréhensible et mots épars, les mots épars pouvant être considérés par certainscorrecteurs comme constituant un texte incompréhensible.
[31] Sandrine Alègre, Efpraxia Papanastasiou, Olivier Delhaye, chercheurs au laboratoire de didactique des langues du Département de Langue et Littérature françaises de l’Université Aristote de Thessaloniki.
[32] Olivier Delhaye, concepteur de l’instrument de notation.
[33] Les courbes sont d’allure gaussienne et les coefficients d’asymétrie sont réduits.
[34] Conseil de l’Europe (2006 : 67 et sq.)
[35] Nous ne disposons pas encore des chiffres qui concernent les résultats de la correction des copies de la session de novembre 2008.
[36] Il a été choisi de comparer les chiffres de deux sessions se déroulant à la même période de l’année (sessions de mai) pour des raisons de fiabilité (importances comparables des populations, neutralisation d’éventuels facteurs parasites).
[37] Les résultats au niveau A ne sont pas pris en compte car, nous ne disposons pas, pour ce niveau, de point de comparaison en mai 2007. Les résultats antérieurs à 2007 ne sont pas non plus pris en compte car les moyennes interlangues étaient moins harmonieuses.
[38] Les données statistiques brutes de la session de novembre 2008 ne sont pas encore publiées.
[39] Transcription latine du sigle du dispositif dénommé Κρατικό Πιστοποιητικό Γλωσσομάθειας en grec (Certificat d’État de Connaissance des langues).
[40] Cf. description dans Ministère de l’éducation nationale et des cultes (2005).
[41] Ces chercheurs sont employés par l’Université nationale Capodistrienne d’Athènes et par l’Université Aristote de Thessaloniki.
[42] En grec : Ενιαίο Πλαίσιο Προγράμματος των Εξετάσεων – ΕΠΠΕ (2003).
[43] Cf. Υπουργείο Εθνικής Παιδείας και Θρησκευμάτων (2003 : 15).
[44] Conseil de l’Europe (2001).
[45] Cf. notamment Αριστοτέλειο Πανεπιστήμιο Θεσσαλονίκης, Φιλοσοφική Σχολή, Τμήμα Γαλλικής Γλώσσας και Φιλολογίας, Τομέας Γλωσσολογίας και Διδακτικής (2008).
[46] Cf. résumé suffisant in Delhaye (2006b).
[47] À prendre au sens prêté par Noizet et Bonniol (1968-1969) d’investigation docimologique qui dépasse le plan du constat et qui permet un perfectionnement du système d’estimation par la connaissance expérimentale des mécanismes en jeu et des causes de distorsion dans leur fonctionnement.
[48] Cf. Υπουργείο Εθνικής Παιδείας και Θρησκευμάτων (2005 : 29-30).
[49] Elles ontétudiées au cours d’autres recherches entreprises par le Département de Langue et Littérature française avec le soutien du Troisième Cadre Communautaire d’Appui et dont les résultats ne sont pas encore publiés.
[50] Cette description n’est pas réalisée par l’auteur de cette grille et peut donc comporter des lacunes.
[51] Il s’agit le plus souvent d’écoles publiques.
[52] Ce temps est régulièrement réévalué.
[53] Ces textes sont à compéter, parfois, au niveau A.
[54] Au sens entendu par Meirieu (1987 : 164-179).
[55] Dans le centre de notation d’Athènes ou de Thessaloniki.
[56] Le travail des évaluateurs des productions écrites ne consiste certainement pas à les corriger, mais nous conserverons cette dénomination souvent adoptée, notamment dans le Cadre Commun du Programme des Examens du KPg (2003).
[57] Mansour (1978) a montré qu’il faut au moins 7 évaluateurs pour assurer une évaluation fiable d’une même production écrite mais que ce nombre peut être sensiblement réduit si ces évaluateurs disposent d’une même grille d’évaluation.
[58] Les formulations exactes sont plus longues : Aucune faute ou très peu, qui ne gênent pas du tout la compréhension – Quelques fautes qui ne gênent pas vraiment la compréhension – Peu de fautes qui commencent à gêner la compréhension – Beaucoup de fautes qui commencent à gêner la compréhension – Beaucoup de fautes qui finissent par gêner quelque peu la compréhension – Beaucoup de fautes ou grosses fautes. Le lecteur doit relire certains passages pour comprendre (traduit du grec). Cf. Première grille en annexe
[59] Calcul de la moyenne des scores attribué par chacun des évaluateurs.
[60] Cf. par exemple Delhaye (2006 : 18-19).
[61] La grille se décline en plusieurs versions suivant le niveau, l’activité langagière (pure production / médiation) ou la session.
[62] Cf. Delhaye (1998 : 57).
[63] Hadji (1997 : 24-28) déduit de cette intrusion du subjectif dans la notation que l’évaluation n’est finalement pas une opération de mesure, mais avant tout un jugement humain. Il revient au concepteur d’une grille de notation de proposer une catégorisation facile des jugements émis.
[64] Le correcteur ne devra donc poser aucun doigt sur les zones grisées de la grille dans ce cas extrême puisque le nombre des objectifs atteints et celui des écarts linguistiques ne sont pas mis en rapport.
[65] Ce cas de figure, rare, ne peut être représenté par les mêmes relations géométriques, c’est pourquoi il figure également en dehors des zones grisées.
[66] C’est pourquoi d’ailleurs, une mention explicite est toujours faite du sujet précis auquel se rapporte chaque grille.
[67] On pourrait objecter que les adjectifs suffisant et efficace renvoient à des notions relatives, mais elles sont clairement explicitées dans la littérature remise aux correcteurs. Cf. Instrument en annexe.
[68] Nous avons reformulé les descripteurs pour éviter le chevauchement qui pouvait exister entre texte incompréhensible et mots épars, les mots épars pouvant être considérés par certainscorrecteurs comme constituant un texte incompréhensible.
[69] Sandrine Alègre, Efpraxia Papanastasiou, Olivier Delhaye, chercheurs au laboratoire de didactique des langues du Département de Langue et Littérature françaises de l’Université Aristote de Thessaloniki.
[70] Olivier Delhaye, concepteur de l’instrument de notation.
[71] Les courbes sont d’allure gaussienne et les coefficients d’asymétrie sont réduits.
[72] Conseil de l’Europe (2006 : 67 et sq.)
[73] Nous ne disposons pas encore des chiffres qui concernent les résultats de la correction des copies de la session de novembre 2008.
[74] Il a été choisi de comparer les chiffres de deux sessions se déroulant à la même période de l’année (sessions de mai) pour des raisons de fiabilité (importances comparables des populations, neutralisation d’éventuels facteurs parasites).
[75] Les résultats au niveau A ne sont pas pris en compte car, nous ne disposons pas, pour ce niveau, de point de comparaison en mai 2007. Les résultats antérieurs à 2007 ne sont pas non plus pris en compte car les moyennes interlangues étaient moins harmonieuses.
[76] Les données statistiques brutes de la session de novembre 2008 ne sont pas encore publiées.
